
If you would like to obtain the exact results that I did, you could use the following code for your dataset:
use http://twtcsl.org/dataset/gss2000.dta
tab race
tab race sex
sum race sex age income
tab race, gen(d)
rename d1 dwhite
rename d2 dblack
rename d3 dother
tab sex, gen(d)
rename d1 dmale
rename d2 dfemale
sum dwhite dblack dother dmale age income if !mi(age) & !mi(income) The results:
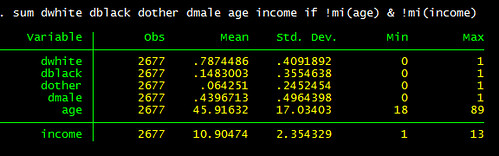
How do we export it? You can use EDIT-COPY TABLE in stata dropdown menu, or write some code to do the work.
estpost sum dwhite dblack dother dmale age income if !mi(age) & !mi(income)
esttab using sum2.rtf, cells("mean(fmt(2)) sd(fmt(2)) min(fmt(1)) max(fmt(0))") nomtitle nonumber replace The export table looks like this:

To obtain three digits after the decimal point, change fmt(2) to fmt(3).
If you require more advanced descriptive statistics tables, for example, if you wanted to determine age and income by race, you could use the following codes:
sort race
by race: eststo: estpost sum age income if !mi(age) & !mi(income)
esttab using grp_sum.rtf, cells("mean(fmt(2)) sd(fmt(2))") replace This result in a neat table:

If you are unable to export tables, check this article


